Test prompts across models simultaneously
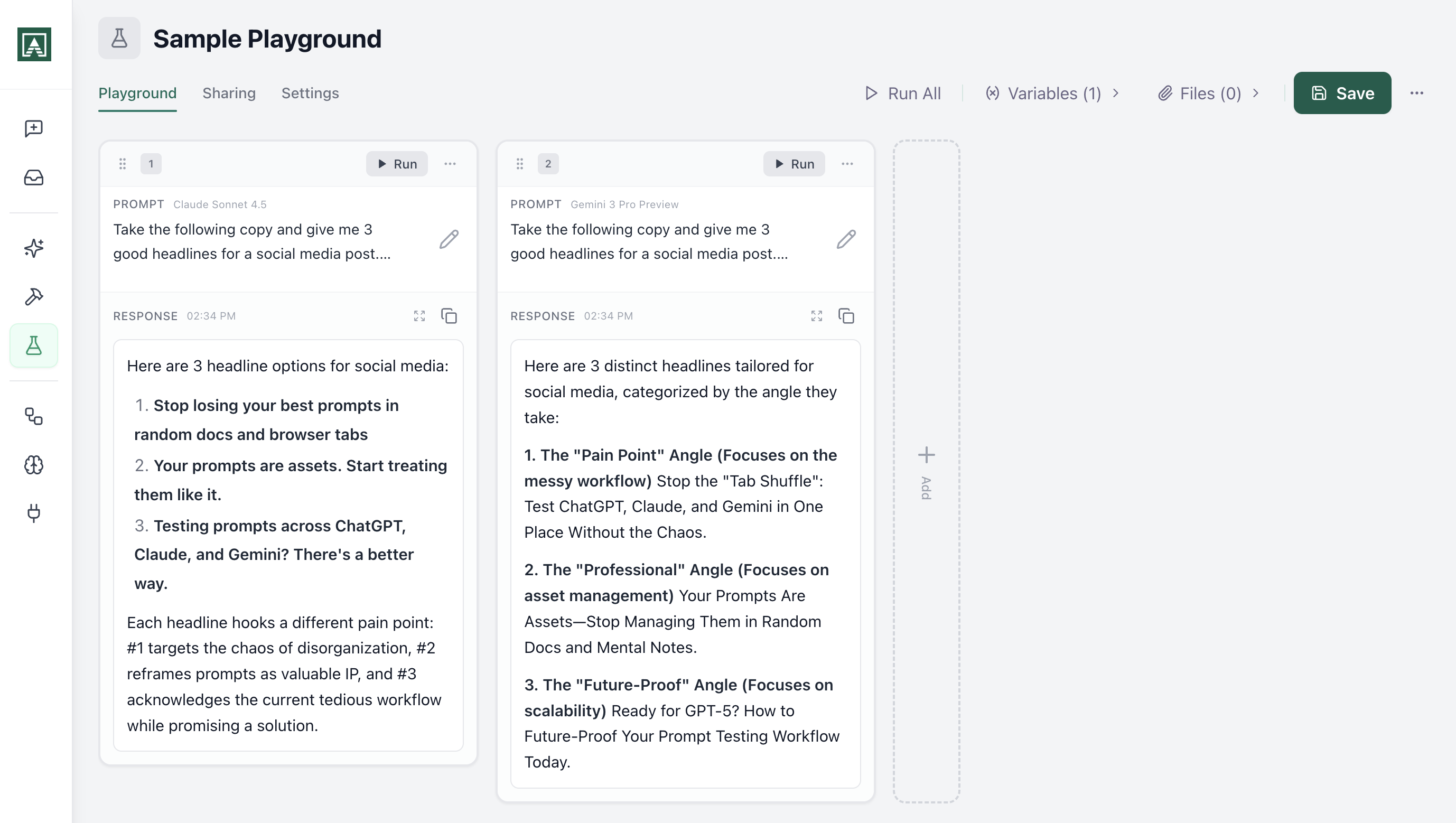
Pick your models. Hit run. Results appear side-by-side. The best prompt on GPT-4 might not be the best prompt on Claude. The only way to know is to test.
Everything you need to test prompts at scale
Multi-model comparison
Run the same prompt against GPT-4, Claude, and Gemini simultaneously. Results appear side-by-side so you can see which model handles your use case best. When a new model launches, add it and retest everything.
Learn about model comparisonReal-time testing with evals
Same prompt, different inputs. Pass in five customer profiles and see how each model handles edge cases. Compare prompt iterations side-by-side. Load two versions, run both, see which performs better. No guessing.
Explore real-time testingSave and share test states
Send a link and your team sees prompts, model configs, and results exactly as you left them. They iterate from there. No screenshots, no copy-pasting, no "what settings were you using?" Access your full prompt library and compare against previous versions.
See sharing in actionExplore more of Aisle
Playgrounds is one part of the platform. Here is what else you can do.
Test before you ship
The best prompt on GPT-4 might not be the best prompt on Claude. The only way to know is to test.